AWS 강의 후다닥 끝내고 챌린지반 수업내용 이제야 복습합니다......
아 배포 특강 복습 언제하지
1. 캐시
1) 캐시
CPU와 메모리 사이의 데이터 전송 레이턴시 개선을 위한 방법
CPU에서 자주 뽑아 쓸것 같은 데이터를 캐시에 따로 저장해놓음
2) 캐싱 알고리즘
아래 두가지를 근거로 메모리에서 데이터 캐싱을 함.
- 시간적 지역성 : 지금 어떤 데이터를 사용했다면 가까운 미래에 재사용을 할 가능성이 있다
- 공간적 지역성 : 지금 어떤 데이터를 사용했다면 그와 인접한 데이터도 사용할 가능성이 있다
예시
const arr = [];
...
const result = [];
const loopCount = 10; // arr.length는 loopCount보다 크다고 가정을 합니다.
for (let i = 0; i < loopCount; i+=1) {
result.push(arr[i] + arr[i + 1]);
}
- 시간적 지역성 : arr[0], arr[10] 을 제외한 나머지 arr의 원소들은 첫번째 루프에서는 오른쪽 피연산자로 사용, 두번째 루프에서는 왼쪽 피연산자로 사용
- 공간적 지역성 : arr이라는 배열 내의 메모리들이 순차적으로 사용
3) 캐시 구성

- 그림에서, L1 캐시는 코어와 가장 가깝고, L3은 코어랑 가장 먼 캐시.
- 거리가 가까울수록 CPU가 데이터를 가져오는 속도도 빠름.
- L1 캐시는 속도가 빠르지만 저장공간을 줄여 데이터를 빠르게 가져오는것에만 집중, 대신 cashe miss 확률은 높음
- L2 L3 캐시는 속도는 빠르지만 저장공간이 넓어 cashe miss가 될 확률이 낮음
4) 캐시 코히런스 문제
데이터를 여러개의 캐시가 동시에 보관할 경우 데이터의 일관성, 무결성을 보장하기 힘듦
다음과 같은 상황에서, Core 1이 val을 8888로 바꾸고 메모리에도 반영을 하였으나, cashe 2에는 반영되지 않음


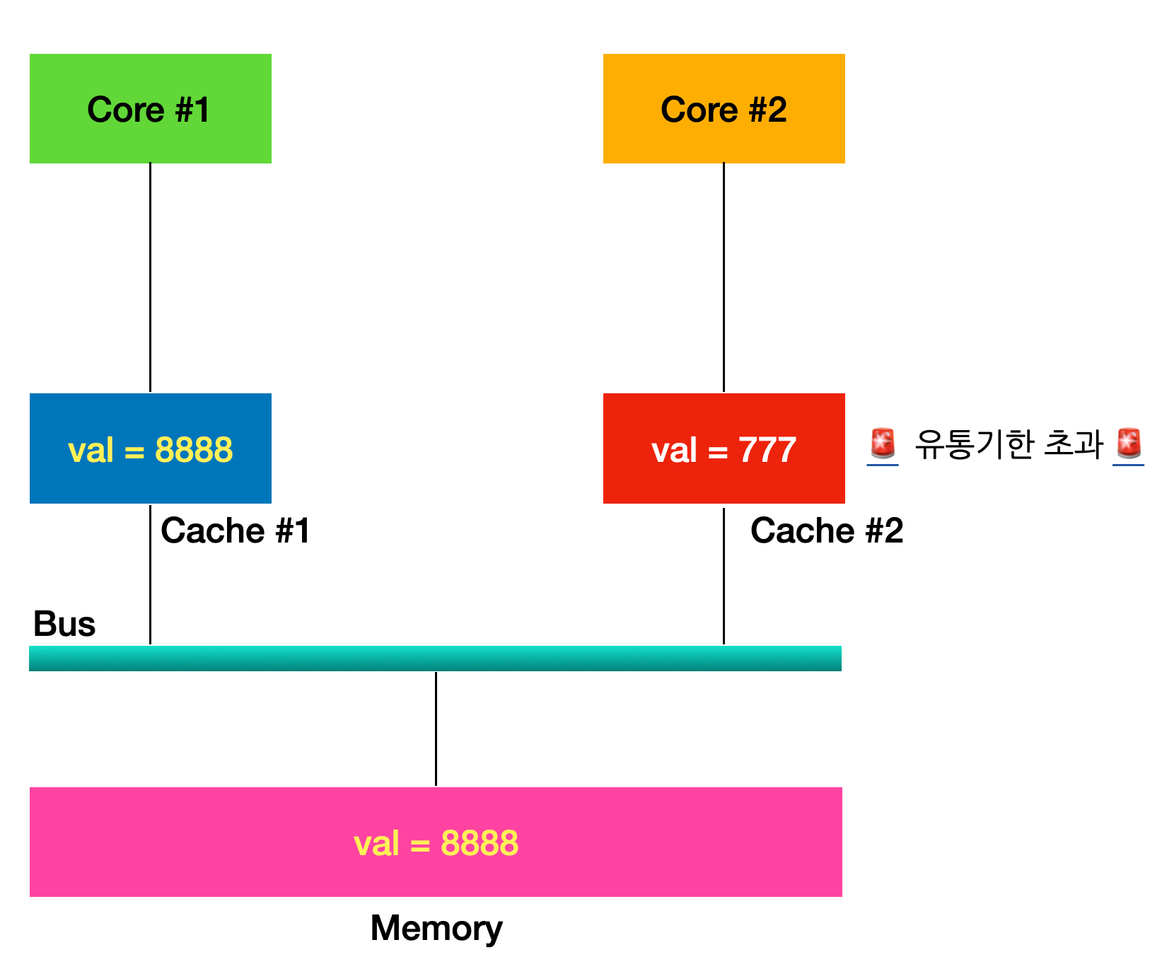
이런 문제를 해결하기 위해 MSI 프로토콜을 사용
5) MSI 프로토콜
각각의 캐시 라인들에 상태를 부여하여 각 캐시 라인의 상태에 따라 최신 값으로 동기화 여부를 결정하는 프로토콜
- S(Shared) 상태 : 가장 기본 상태, 동기화 완료 직후 or 값에 변함이 없을 경우 S 상태 유지
- M(Modified) 상태
- 코어가 캐시 및 메모리의 값을 새롭게 바꾸려고 할 때 M 상태로 변환
- 메모리는 해당 데이터가 새롭게 본인에게 쓰이기 전까지는 다른 코어의 요구를 거부
- I(Invalid) 상태
- 캐시 라인의 상태가 유효하지 않음
- M 상태로 만들고 새롭게 데이터를 쓰려는 코어가 본인의 캐시 라인을 제외한 다른 캐시 라인들의 상태를 전부 I 상태로 바꿔놓음
- 즉, M 상태로 만든 코어가 모든 코어에게 경고하는 상태
예시
- 양쪽 라인 모두 S 상태 유지, 코어 2가 val 값을 알아내려고 했으나, 캐시 2에서는 캐시 미스, 메모리에서 val을 가져와 캐시 2에 반영
- 코어 2가 캐시 라인의 상태를 S>M으로 바꾸면서 캐시의 val 값을 수정, 다른 캐시 라인들을 모두 I로 변경
- 코어 1이 val 값을 불러올 때, 캐시 1의 상태가 I이기 때문에 메모리에서 불러오려고 함
- 메모리는 S 상태의 캐시라인이 아니기 때문에 코어 1의 요청에 응답 X, 대신 코어 2가 cache to cache transfer을 코어 1에 시행
- 코어 2는 메모리에 최신 val 값을 보내서 갱신 > 이후 캐시 1, 캐시 2, 메모리 상태가 모두 같으므로 캐시 라인은 모두 S 상태로 변경
- 캐시와 메모리의 값은 최신 상태를 보장





2. 메모리
1) 저장공간
1) 속도 : CPU 레지스터 > L1 캐시 > L2 캐시 > L3 캐시 > 메모리 > 디스크
2) 용량 : 디스크 > 메모리 > L3 캐시 > L2 캐시 > L1 캐시 > CPU 레지스터
속도와 용량은 반비례
여기서, 디스크는 메모리에 비해서 I/O 속도가 매우 느리기 때문에 디스크 I/O를 줄여야 프로그램 성능에 도움 됨
2) 캐시와 메모리, SRAM & DRAM
캐시는 SRAM(Static Random Access Memory)으로, 메모리는 DRAM(Dynamic Random Access Memory)으로 구성
- DRAM : 커패시터로 구성, 절연이 완벽히 되지 않아 시간이 지날수록 전하가 누출되어 데이터 손실 > 주기적으로 저장된 데이터를 읽고 다시 써야 함 > Refresh를 짧은 주기에 Dynamic하게 하는 메모리
- SRAM : 트랜지스터로 구성된 플립플롭 회로 사용, DRAM과 달리 리프레시 필요 X, 읽기 쓰기 속도가 매우 빨라 캐시로도 사용 가능
+) DRAM은 SRAM에 비해 비트당 면적이 작아 비용이 저렴...
이런 이유들로 속도를 챙기는 캐시는 SRAM을, 용량을 챙기는 메모리는 DRAM 사용
3) 프로세스의 메모리 구조

프로세스(실행중인 프로그램)이 메모리에 올라오면 위 구조를 가지게 됨.
- 스택
- 일반적으로 함수 스코프에 해당되는 데이터들을 담음
- 지역변수, 파라미터 등을 담음
- 재귀함수 호출의 경우 종료 조건을 제대로 설정하지 않으면 stack overflow 발생
- 힙
- 동적인 메모리 할당
- js에서는 기본적으로 참조 타입(ex. 객체)를 힙에 저장
- java에서는 new 키워드 사용 시 힙에 저장
- 데이터
- 일반적으로 전역 스코프에 해당되는 데이터 포함
- 전역 변수, static 변수를 담음
- 텍스트
- 실행 코드와 함수를 담음
- CPU가 이 텍스트 영역에 저장된 명령을 하나씩 가져가서 처리
4) 가상 메모리
- 한 pc에서 용량이 큰 여러 프로그램들을 돌려 램의 용량을 초과해도 프로그램이 느려질 뿐 종료되지는 않음
- 각 프로세스마다 각각의 가상 메모리를 할당받음 > 다른 프로세스의 가상 메모리를 침범 X
- 각 프로세스들은 64비트 운영체제 기준 2^64 만큼의 가상 메모리 공간을 사용 가능
- 근데, 2^64 만큼의 가상 메모리 공간에 비해 램(8GB)의 용량이 작음 > 물리 메모리 용량보다 더 많은 용량을 쓰기 위해 디스크를 사용
5) 가상 메모리의 시스템 유지
프로세스 당 물리 메모리 영역 크기 이상으로 메모리를 사용해야 하기 때문에, 프로세스는 가상 주소로 메모리의 영역을 관리함
- 페이지 : 가상 메모리에서 사용되는 메모리 영역을 일정한 크기로 나눈 블록
- 프레임 : 물리 메모리에서 사용되는 메모리 영역을 일정한 크기로 나눈 블록
- 프로세스 가상 주소에서, 현재 사용중인 페이지는 실제 물리 메모리 영역(프레임)에 저장, 그리고 저장되는 프레임 위치에 대한 정보는 Page Table에 저장
- 사용중이지 않은 페이지는 디스크로 이동, 즉 디스크는 쓰이지 않는 페이지를 담는 임시 저장공간 역할
쓰이지 않는 영역을 다시 아용할 경우
- 특정 프로세스의 페이지가 페이지 테이블에 매핑 규칙이 있는지 확인
- 매핑 규칙이 없을 경우(page fault) OS는 프로그램 실행을 잠시 중단시킨 후 새로운 프레임을 확보
- 새 프레임을 확보하려면 교체할 페이지를 선택해야 하는데, LRU 알고리즘을 주로 사용
- LRU(Least Recently Used) 알고리즘 : 가장 오랫동안 사용되지 않은 페이지의 프레임 영역을 선택
- 새 프레임 영역이 확보되면 해당 페이지가 확보된 프레임으로 매핑됨 (page swap) > 이후 OS에서 프로그램 재실행
물리 메모리 영역이 상대적으로 부족해서 잦게 page swap을 발생할 경우 thrashing이라는 성능 저하가 발생하기도 함..
'TIL' 카테고리의 다른 글
| TIL 240712 - 랭킹 알고리즘 (0) | 2024.07.12 |
|---|---|
| TIL 240711 - 알고리즘 코드카타 리뷰 - 모음사전 (0) | 2024.07.12 |
| TIL 240709 - 알고리즘 코드카타 리뷰 - 주차요금 계산 (0) | 2024.07.09 |
| TIL 240708 - class-validator, custom validator (0) | 2024.07.08 |
| TIL 240705 - 알고리즘 코드카타 리뷰 - 타겟 넘버 (0) | 2024.07.05 |